À Douala, un créateur de 22 ans poste une vidéo en camfranglais. À Yaoundé, un podcast bilingue circule sur WhatsApp. Une blague filmée en ewondo franchit les 50 000 vues en trois jours. Ces contenus ne sont plus de simples divertissements. Ils deviennent des actifs négociables, matières premières recherchées par les agences spécialisées en intelligence artificielle, qui cherchent à les collecter, annoter et monétiser. Chaque jour, cette production atteint l'ordre du pétaoctet à l'échelle du continent. Le Cameroun y contribue massivement. D'autres valorisent. L'enjeu de la décennie tient dans cette asymétrie.
12,4 millions d'internautes, des milliards de signaux exploitables
En janvier 2025, le pays comptait 12,4 millions d'utilisateurs d'Internet, soit 41,9 % de la population, selon DataReportal. Le taux de pénétration mobile atteint 86,3 %, avec 25,5 millions de connexions actives. Parmi elles, 83,6 % relèvent du haut débit, un niveau suffisant pour produire et diffuser des formats exigeants comme la vidéo, l’audio longue durée et les podcasts filmés. Ces statistiques révèlent une réalité économique concrète : chaque jour, des millions de Camerounais produisent des contenus audiovisuels complexes. Leurs expressions faciales, intonations vocales et nuances culturelles constituent des données fondamentales que les modèles d'IA mondiaux peinent encore à décoder. Avec un âge médian de 18 ans et un taux d'urbanisation de 60,2 %, le pays dispose d'un vivier de créateurs numériques concentré dans les bassins de Douala, Yaoundé, mais aussi Garoua, Bafoussam et Kribi, capable d'alimenter cette demande sur la durée.
Ce que les agences collectent vraiment
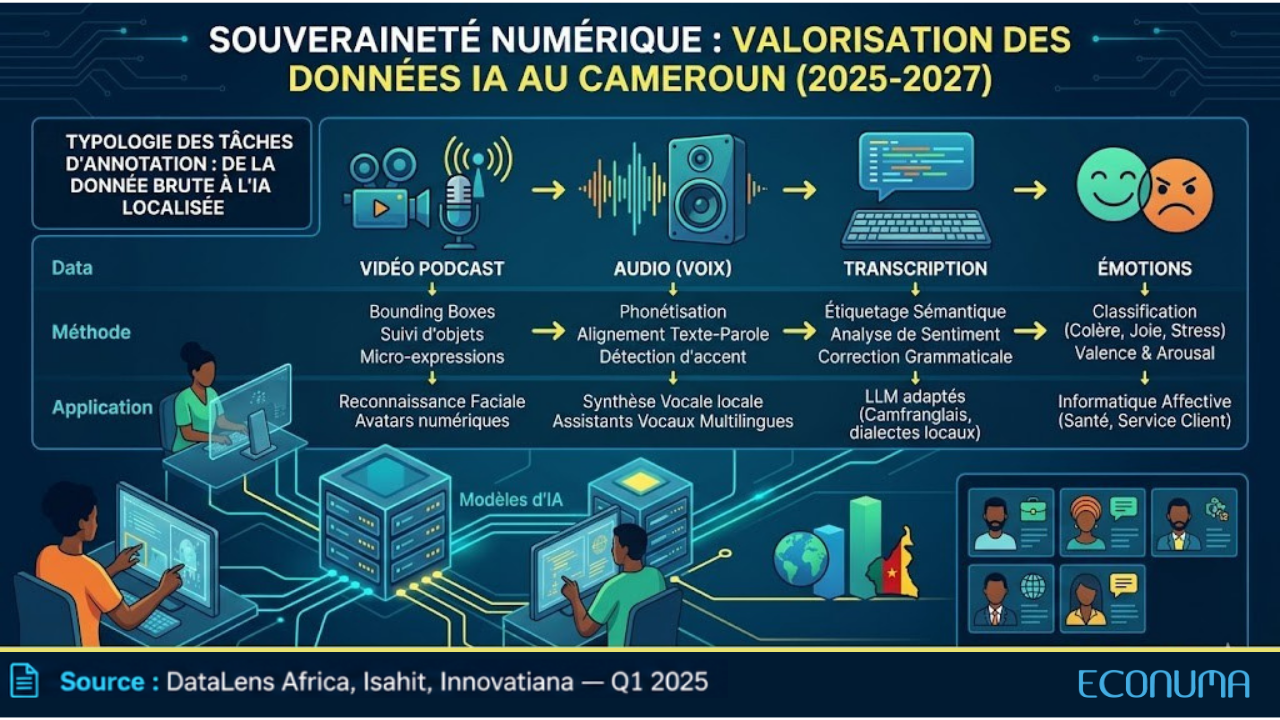
Des entreprises spécialisées comme Isahit, Innovatiana ou DataLens Africa ne recherchent pas la vidéo en tant que telle. Elles exploitent les informations qu’elle contient : l’accent bamiléké dans une voix, une intonation d’urgence en ewondo, ou la structure narrative d’un récit en pidgin. Ces éléments servent à des tâches d’annotation précises, comme la segmentation vidéo, la transcription ou la classification des émotions. Les données obtenues alimentent ensuite l’entraînement de modèles de reconnaissance vocale, d’avatars numériques et d’assistants conversationnels.
L'argument technique est limpide. Une IA capable de détecter la fraude bancaire au Cameroun ou d'affiner un diagnostic médical en zone rurale exige des milliers d'échantillons traités par des natifs qui maîtrisent les subtilités du terrain. Sans cette couche de compréhension locale, le modèle échoue ou produit des résultats biaisés.
Les podcasts vidéo, format premium du Machine Learning
Parmi les formats convoités par les chercheurs en apprentissage automatique, les podcasts vidéo occupent une place à part. Ils associent un audio de haute qualité à la capture des expressions faciales, soit les deux types de données nécessaires pour affiner l’analyse des émotions et concevoir des assistants vocaux adaptés au contexte local. Un modèle entraîné sur ce type de contenu multimodal apprend simultanément la prosodie, les micro-expressions et les marqueurs culturels d'une conversation. Pour les marchés africains, ce format constitue une ressource rare que les bases anglophones ou sinophones ne peuvent pas fournir.
Le biais de genre, angle mort de la collecte
La collecte massique comporte un piège. Sur Facebook, plateforme dominante au Cameroun avec 5,45 millions d'identités actives, l'audience reste majoritairement masculine. Si les jeux de données reflètent ce déséquilibre, les modèles entraînés reproduiront un biais de genre systémique : reconnaissance vocale moins performante pour les voix féminines, analyse de sentiment calibrée sur des schémas masculins, assistants conversationnels aveugles aux registres langagiers des femmes. Les agences de labeling sérieuses corrigent activement cette asymétrie en diversifiant leurs panels d'annotateurs. Celles qui l'ignorent fabriquent des modèles déficients.
250 langues, et des modèles globaux sourds à la plupart

Le Cameroun recense 250 langues nationales. Les grands modèles de langage existants Whisper d'OpenAI, entraîné sur 680 000 heures d'audio dominé par l'anglais, l'espagnol et le français standard affichent une précision médiocre sur les dialectes et accents ruraux camerounais. Combler ce fossé suppose un travail colossal : pour une seule langue, des centaines d'heures d'enregistrement doivent être collectées puis traitées manuellement.
AWA (Andakia), Masakhane et WAXAL s'attaquent aux langues sous-représentées. Masakhane, réseau panafricain de chercheurs en traitement du langage naturel, agrège des contributeurs camerounais pour construire des corpus multilingues. WAXAL développe des bases vocales pour le haoussa, parlé au Nord-Cameroun. La progression reste lente face à l'ampleur de la tâche. Paradoxalement, cette rareté technique transforme les créateurs locaux en fournisseurs stratégiques : ceux qui négocient leurs licences capturent une part des revenus, les autres les cèdent gratuitement, sans le mesurer.
Propriété intellectuelle : la friction centrale
Le droit d'auteur protège l'œuvre finale. L'IA, elle, déconstruit les œuvres pour en extraire des schémas statistiques, un usage imprévu par les cadres juridiques traditionnels. Un créateur camerounais diffusant un sketch en pidgin verra ses intonations capter pour calibrer un assistant vocal étranger.
Face à cette réalité, la CISAC milite internationalement pour la reconnaissance contractuelle des usages dérivés. Au Cameroun, une transition s'amorce : les contrats de licence rémunérés remplacent la diffusion passive. Ce passage d'un modèle extractif à transactionnel conditionne la capacité des créateurs locaux à monétiser directement leur audience. La valeur marchande des contenus multimédias, résidant dans leur apport au progrès technologique, doit prioritairement générer des profits pour ceux qui produisent cette matière première.
Un cadre juridique qui change la donne
Le législateur a posé un jalon. La loi n° 2024/017 du 23 décembre 2024, relative à la protection des données à caractère personnel, impose désormais un consentement explicite pour toute collecte destinée à l'entraînement de modèles d'IA. Les agences disposent d'un délai jusqu'au 23 juin 2026 pour atteindre la conformité totale. L'ANTIC, régulateur central, veille à ce que la collecte de données biométriques ne glisse pas vers ce que les travaux préparatoires des CONIA 2025 qualifiiaent de « colonisation algorithmique ». Les sanctions administratives sont prévues en cas de manquement.
Dimension souvent ignorée : la loi accorde au créateur un droit à l'effacement. Tout individu peut exiger le retrait de son identité numérique des jeux d'entraînement. Ce levier juridique, s'il est exercé à grande échelle, pourrait reconfigurer le rapport de force entre créateurs locaux et plateformes d'IA étrangères.
Ce cadre joue un double rôle. Il protège le créateur. Il rend aussi le marché camerounais plus crédible aux yeux des donneurs d'ordre internationaux : un environnement régulé attire des contrats de licence structurés plutôt que des extractions sauvages.
Des métiers concrets, accessibles aujourd'hui

L'économie de la donnée génère déjà des emplois au Cameroun. À Douala, CAAP Formation propose des cycles en apprentissage automatique et apprentissage profond. L'ETIIAC réunit des experts pour former les chercheurs locaux. Sur Jobartis Cameroun, des offres de « Tuteurs IA » francophones ciblent des profils capables de corriger les biais culturels des modèles de langage.
Ces rôles annotateur, délégué à la protection des données, ingénieur prompt dessinent une filière structurée que des TPE camerounaises peuvent intégrer dans leur stratégie de recrutement dès maintenant. (Marché de l'emploi Cameroun 2026 : Le digital bouscule le recrutement dans le PME)
Rapatrier les serveurs : la souveraineté physique
Le débat sur la souveraineté numérique reste abstrait tant que les serveurs restent à l'étranger. Actuellement, 99 % de la capacité mondiale de stockage se situe hors d'Afrique selon le rapport publié par l'Africa Data Center Association (Adca) et Rising Advisory. Cette dépendance géographique fragilise la sécurité des informations stratégiques camerounaises et alourdit les temps de latence pour les services locaux.
Le rapatriement de data centers sur le sol national s'inscrit comme une priorité politique. Des infrastructures conformes aux standards internationaux permettraient de réduire la latence, protéger l'intégrité des données personnelles au regard de la loi de 2024, et attirer des investissements technologiques durables. Sans capacités de stockage locales, l'IA camerounaise restera un concept vulnérable, tributaire de décisions prises sur d'autres continents.
Producteur ou transformateur : le choix binaire
L'IA pourrait générer 1 000 milliards de dollars de PIB supplémentaire pour l'Afrique d'ici 2035, selon un rapport de la Banque africaine de développement. Pour le Cameroun, cette projection implique un choix stratégique : continuer à être un fournisseur de contenus bruts exportés vers des serveurs hors de la CEMAC, où se concentre l'essentiel de la capacité mondiale de stockage, ou investir dans des infrastructures locales, former des spécialistes du traitement et développer des modèles souverains adaptés aux réalités de l'Afrique centrale.
Les CONIA 2025, pilotées par le MINPOSTEL sous l'égide du Premier Ministre, ont proposé une feuille de route en quatre axes : agriculture, santé, finance et gouvernance. Si l'orientation est établie, le défi reste de mesurer la rapidité de sa mise en œuvre face à des concurrents africains comme le Kenya, le Nigeria et le Rwanda, qui progressent déjà.
Sans maîtrise de ses propres jeux de données, le Cameroun restera consommateur de solutions d'IA déconnectées de ses réalités sociales et économiques. La donnée brute attend sa transformation en intelligence souveraine.
Le prix à fixer
La donnée audiovisuelle camerounaise possède une valeur marchande réelle. Le débat ne porte plus sur sa démonstration. Il porte sur une question de pouvoir : qui fixe le prix, et qui signe le contrat.